
JavaPresse: Critical Review Filtering
Feedback on JavaPresse Coffee Grinder
Background
JavaPresse produces and sells possibly the most popular manual coffee grinder in the world which is available for purchase on various Ec-commerce stores including the company's website and Amazon.
The majority of the cutomers that have purchased the product seem to have been satisfied with unsatisfactory feedback seeming to be relatively low.
Data Description
Data was acquired from Amazon using web scraping which includes
- 5000 descriptive reviews left by various customers;
- The corresponding star rating on a scale of 1-5 (with 1 being the lowest).
The dataset used for the project is available on Kaggle and can be accessed using this link.
Methodology
The master data contains reviews that are divided into five different classes and a preview is shown below.

Visualization of the class distributions after reccategorization into two different classes, namely positive/non critical (denoted as 1 in the chart) and negative/critical (denoted as 0 in the chart) shows that the latter are in the minority as mentioned earlier.

The text data was cleaned using a variety of techniques including removal of special characters and stopwords through tokenization.
Various machine learning algorithms including a simple feedforward neural network were selected to build a classification model through undersampling and assigning class weights using tf-idf (and word embeddings for the latter) to evaluate their performances on the available data.
Since the data is highly imblanced, conventional evaluation techniques like accuracy weren't deemed suitable to evaluate model performance; Recall, Precision & F1 metrics for the minority class were used instead by defining custom scorers.
Results
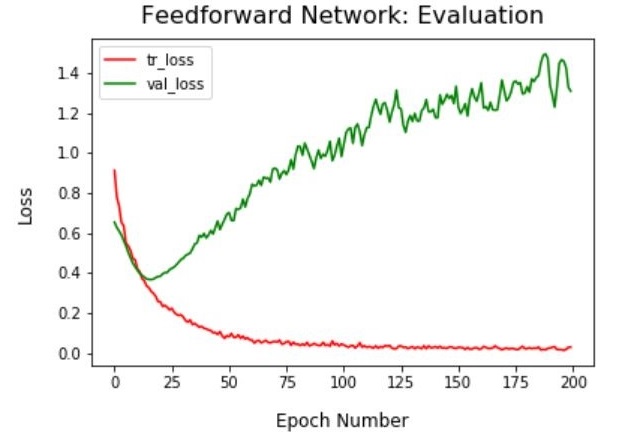
The neural network model was overfitting (most likely due to lack of sufficient training data as shown below) and was outperformed by logistic regression and support vector classifiers.
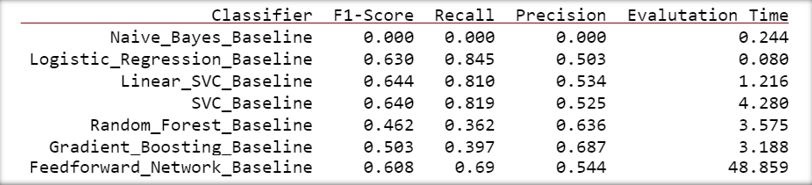
Although it was able to produce recall scores of up to 85 %, precision for various model using Undersampling was lower than 50 % for the target class. Comparatively, using class weights (with both tf-idf and word embeddings) resulted in over 80 % recall, 50 % precision and higher F1-Scores.
Finally, a grid search was performed for hyperparameter tuning to improve model performance (whilst modeling with class weights); the corresponding confusion matrices are shown below.

Grid Search through Pipelines using cross validation seems to have improved F1-Scores slightly for the target class.

A copy of the working notebook is available here and a short video presentation is available here.
Conclusion
Logistic Regression and Support Vector classifiers with tf-idf and Singular Value Decomposition provide over 50 % precision and 80 % recall relatively quickly.
Word Embeddings can be used to improve the accuracy of the model with the help of LSTM/GRU but additional data will be required to implement them effectively.